Client/Server Programming -- Week 4
Introduction
This week we'll cover some advanced RMI topics.
Note that the links from this page are to handouts that will be distributed the night of class. Only print out those handouts if you could not attend class.
Main topics this week:
Multithreading in the Server
Thread States
Controlling Threads
Interacting Threads
Synchronization to Avoid Race Conditions
Deadlock
Using Wait and Notify
Remote Garbage Collection
Downloading Client Code
Dynamic Server Activation
Next Week
RMI automatically will execute each client in a separate thread. There will only be one instance of your server object no matter how many clients, so you need to make sure that shared data is synchronized appropriately. In particular, any data that may be accessed by more than one client at a time must be synchronized.
Also note that you cannot depend on data in the server to remain the same between two successive calls from a client. In our rental car example from the first class, a client may get a list of cars in one call, and in a later call try to reserve the car. In the meantime, another client may have already reserved that car. The server must double-check all data coming from the client to protect against this sort of error. Also for this reason, the server should never pass to the client any direct pointers to its internal data structures (such as an array index), as that type of data is highly likely to change before the client tries to use it.
Multithreading can also introduce very difficult to find bugs into your program. The types of bugs introduced because of multithreading are called "race conditions". A race condition is a bug that is timing sensitive. In other words, the bug only happens when several conditions happen at exactly the same time. With multithreading, the possibility of race conditions increases.
Unfortunately, it's almost impossible to know if a multithreading program has bugs or not. Each thread runs at the same time as the other threads. A computer with a single CPU, however, cannot really run multiple instructions at the same time. So it runs instructions from one thread for a while, and then runs some instructions from another thread. You have no way of knowing exactly when a thread may be interrupted and another thread run.
Since RMI automatically runs client calls in separate threads, you do not need to use Thread or Runnable yourself.
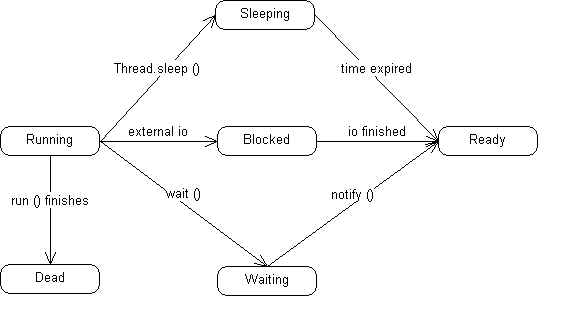
You still need to worry about thread states, however, in RMI. A thread can be in one of several states. These include:
Running -- The thread is currently executing.
Dead -- The thread has completely finished executing, and will never execute again. This typically means that the client call to the server has completed.
Ready -- The thread can execute, but is currently not executing. The CPU has switched to another thread and will get back to this one in time.
Blocked -- A blocked thread is waiting for some external event to finish. Examples would include a thread that is trying to read from a file. The thread will block at the call to read from the file, and not continue executing until the read is finished. In this way, a thread that starts an external task will allow other threads to run until that external task is finished.
Waiting -- A thread can wait for other threads to finish work it needs to use, by calling the wait () method. A thread that is waiting for other threads to finish some work will not execute until those threads call the notify () method.
Sleeping -- A thread can voluntarily put itself to sleep for a certain period of time. The thread will start executing again only after the given period of time has passed. The thread puts itself to sleep using the Thread.sleep () method. A thread should put itself to sleep if it only wants to execute every so often.
There are various methods for controlling threads. We've seen Thread.start () to begin a thread. Thread.sleep () allows a thread to sleep for a specific period of time.
There's also Thread.yield (), which allows a thread to voluntarily give up control of the CPU to allow other threads to execute. If there are no other threads to execute, the thread will continue immediately.
Java keeps a queue of threads called the "ready queue". These are threads that are in the Ready state. Threads go from the Running state into one of the other states via method calls. For example, a thread that is Running will go into the sleeping State when Thread.sleep () is called. When the time period for the sleep is over, the thread goes into the Ready state and is placed into the ready queue. Whenever Java needs to figure out which thread to execute next, it pulls a thread from the ready queue.
Here's a diagram of how threads move from state to state:
The thread transitions from Ready to Running when Java decides to run the thread some more. There's also a transition from Running directly to Ready when the thread uses the Thread.yield method to voluntarily give up control of the CPU.
There's a method called Thread.interrupt that can be used to interrupt a thread that is waiting, sleeping, or blocked. The thread will begin executing and will receive an InterruptedException.
Most threads must interact with other threads in some way. This interaction can give rise to various sorts of problems. Let's look at an example. The problem is to have one thread that produces data, and one or more threads that consume that data (you'll also hear these refered to as writers and readers). Here are the two classes we'll look at:
class Producer implements Runnable
{
private LinkedList data;public void setList (LinkedList l)
{
data = l;
}public void run ()
{
while (true)
{
data.add ("Hello");try
{
Thread.sleep (1 + (int) (Math.random () * 1000));
}
catch (InterruptedException e)
{
/* If we were interrupted, go ahead and end */
break;
}
}
}
}class Consumer implements Runnable
{
private LinkedList data;public void setList (LinkedList l)
{
data = l;
}public void run ()
{
while (true)
{
if (data.size () > 0)
System.out.println (data.removeFirst ());try
{
Thread.sleep (50);
}
catch (InterruptedException e)
{
/* If we were interrupted, go ahead and end */
break;
}
}
}
}
The producer thread will add a String to the linked list at random intervals, anywhere from 1 to 1000 milliseconds. The consumer thread will check for a new string every 50 milliseconds. If a string is found, it will be printed to the screen.
What is wrong with this way of having threads interact via sleep ()?
Even if we fix that, what might happen if we have multiple readers operating at the same time? There's a race condition that can cause incorrect results, depending on how the threads run.
Synchronization to Avoid Race Conditions
The way to avoid race conditions is to synchronize access to any shared resources. Any data members that are accessed by more than one thread count as resources. When you synchronize access to shared resources, you are saying that only one thread at a time can access those resources.
The key to using synchronization is to identify what are known as "critical sections" of code. A critical section is a section of code that actually uses some sort of shared resource. We synchronize only these critical sections of code.
Note that synchronization is only one way to avoid race conditions. It is the method used in Java, but not the only method used in other languages. In the operating systems course you'll learn about other methods to avoid race conditions.
When you use synchronization, you must ask for a lock on a shared resource. If the lock is already taken by another thread, you will wait until the lock is available again. If the lock is available, your critical section will execute. When the critical section is done, the lock will be released automatically.
In Java, we synchronize a critical section of code using the synchronized keyword. When we synchronize, we need to give the reference of the resource to lock. For example, to lock on the LinkedList in the example above.
class Producer implements Runnable
{
private LinkedList data;public void setList (LinkedList l)
{
data = l;
}public void run ()
{
while (true)
{
synchronized (data)
{
data.add ("Hello");
}try
{
Thread.sleep (1 + (int) (Math.random () * 1000));
}
catch (InterruptedException e)
{
/* If we were interrupted, go ahead and end */
break;
}
}
}
}class Consumer implements Runnable
{
private LinkedList data;public void setList (LinkedList l)
{
data = l;
}public void run ()
{
while (true)
{
synchronized (data)
{
if (data.size () > 0)
System.out.println (data.removeFirst ());
}try
{
Thread.sleep (50);
}
catch (InterruptedException e)
{
/* If we were interrupted, go ahead and end */
break;
}
}
}
}
This prevents two readers from conflicting with one another, since as soon as one reader enters the critical section, no other object can get a lock on the linked list until that reader finishes the critical section.
You can also synchronize and entire method in an object, like this:
class Foo
{
public synchronized void doSomething ()
{
...do something...
}
}
If you synchronize an entire method, the lock you are getting is on the instance of the object in which that method lives. So it's the exact same effect as doing:
class Foo
{
public void doSomething ()
{
synchronized (this)
{
...do something...
}
}
}
You always need to make sure that you're getting locks on the right objects. Two synchronized blocks that are getting locks on different objects will not prevent each other from running.
Any time that you have synchronization, you have the potential for deadlock. Deadlock is when thread A is waiting on a resource currently being used by thread B, and thread B is waiting on a resource currently being used by thread A. Neither thread can continue. (Show the dining philosophers example)
Preventing deadlock usually means imposing an ordering on the resources, such that everyone is always trying to get the same resource first. That way, the one that gets it can continue on and the rest will wait for that resource before getting locks on any other resources.
Deadlock can also happen in an RMI application when a client makes a call into the server and the server makes a call back to that same client, if both client and server are synchronized. (Show diagram)
We said that using sleep for the reader was not very efficient. An alternative to using sleep that is more efficient is using wait and notify. These are methods on the Object class, so any object can call them. Both wait and notify must be performed inside a synchronized block.
Calling wait gives up the CPU and moves the thread to the Waiting state, as well as releasing the lock the thread had on the synchronized object. When another thread calls notify from within a syncrhonized block with a lock on the same object as the thread that called wait, the thread that called wait is moved out of the waiting state and into the Ready state. But, remember, the call to wait was inside a syncrhonized block. So before the thread can actually be run again, it must regain the lock it had. So it will have to wait until it can get the lock again before continuing execution. Here's a diagram of how this flows:
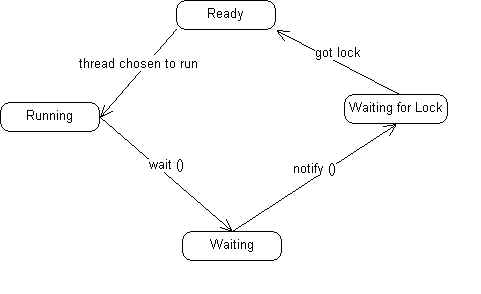
The use of wait and notify is efficient, because a thread will not wake up until there is actually something for it to do. There are some exceptions to this. A thread that is Waiting will wake up if it is interrupted. That is why a call to wait () must catch the InterruptedException. A thread that is Waiting will wake up if the timeout for the wait () call is reached...this means that the thread will only wait a certain amount of time before continuing.
Here are the various wait methods that you can use:
void wait () -- Thread will wait an infinite amount of time. This call will only return if the thread was notified, or interruped. Thread gives up control of the CPU.
void wait (long timeout) -- Thread will wait for the given number of milliseconds. After that number of milliseconds, the thread will resume executing, even if there has been no notify call made. Thread gives up control of the CPU.
void wait (long timeout, int nanoseconds) -- Thread will wait for the given number of milliseconds and nanoseconds. After that amount of time, the thread will resume executing, even if there has been no call to notify made. Thread gives up control of the CPU.
void notify () -- Thread notifies one other thread that is waiting inside a lock on the same object as this thread has locked. In other words, the argument to synchronized must have been the same for both threads. The current thread retains control of the CPU.
void notifyAll () -- Thread notifies all other threads that are waiting inside a lock on the same object as this thread has locked. The current thread retains control of the CPU.
Let's look at our producer/consumer example, using wait and notify instead of sleep. This also moves the linked list into a separate object and synchronizes the methods on that object. This keeps the producer and consumer from needing to synchronize and reduces the errors possible with multithreading.
class DataStore
{
private LinkedList data = new LinkedList ();
public synchronized void insert (String s)
{
data.add (s);
notifyAll ();
}
public synchronized String get ()
{
while (data.size () == 0)
{
try
{
wait ();
}
catch (InterruptedException e)
{
/* Do nothing if we were interrupted. Let the while loop
do another wait if the data store is still empty */
}
}
return (String) data.removeFirst ();
}
}
class Producer implements Runnable
{
private DataStore data;
private int num;public void setDataStore (DataStore ds)
{
data = ds;
}public void setNum (int n)
{
num = n;
}public void run ()
{
while (true)
{
System.out.println ("Producer adding data");
data.insert ("Hello");
try
{
Thread.sleep (1 + (int) (Math.random () * 1000));
}
catch (InterruptedException e)
{
/* If we were interrupted, go ahead and end thread */
break;
}
}
}
}class Consumer implements Runnable
{
private DataStore data;
private int num;
public void setDataStore (DataStore ds)
{
data = ds;
}
public void setNum (int n)
{
num = n;
}
public void run ()
{
while (true)
{
System.out.println ("Consumer " + num + ":" + data.get ());
}
}
}
Note that we still use sleep for the producer...that is a legitimate use of sleep, in a thread that is creating data for others to use. But for the consumer, we use wait instead (inside the DataStore.get method). The producer uses notify (inside the DataStore.insert method) to wake all consumer threads when it adds data. You can run this example using a main that creates several instances of producers and consumers and runs them, such as:
class ThreadTest
{
public static void main(String[] args)
{
DataStore ds = new DataStore ();
Consumer c = new Consumer ();
c.setDataStore (ds);
c.setNum (1);
new Thread (c).start ();
c = new Consumer ();
c.setDataStore (ds);
c.setNum (2);
new Thread (c).start ();
c = new Consumer ();
c.setDataStore (ds);
c.setNum (3);
new Thread (c).start ();
c = new Consumer ();
c.setDataStore (ds);
c.setNum (4);
new Thread (c).start ();
Producer p = new Producer ();
p.setDataStore (ds);
p.setNum (1);
new Thread (p).start ();
p = new Producer ();
p.setDataStore (ds);
p.setNum (2);
new Thread (p).start ();
}
}
Here, we create four consumers and two producers. You can run this to see the order in which producers and consumers process data. There are still things we would need to do to make this a realistic example. Both the producer and consumer threads should have methods that could be called to tell the thread to stop. These methods would set a flag that the run method would check to see if the thread should stop or not. We may also need to set priorities on the threads depending on the problem we're solving. You can set some priorities on the above threads to see how that changes when each thread is run.
Multithreaded programming is extremely difficult to get right for any complex problem. You always want to keep the critical sections as small as possible, so they're only dealing with the resources that are shared. If possible, encapsulate the synchronization code in a class that handles the shared data. This limits the number of places you need to put synchronization code, and so reduces the chances for error. But no matter how good your synchronization code, there are probably still going to be errors that will only show up after a month or two of use.
RMI does have a way for the server to know if all the clients have disconnected, so that the server objects can clean themselves up. This is not foolproof...for example, there is no way for RMI to tell the difference between a client that has disconnected and a client that has simply not done anything for a while.
This only works on any remote object (e.g. objects that extend UnicastRemoteObject). Note that any remote object that is registered with rmiregistry (such as the main server object) will always have a reference to it kept by rmiregistry. So those objects will never be notified that they can be garbage collected. If, however, you have other remote objects, that are not registered with rmiregistry, you could use this technique with them.
A remote object can ask to be notified when all client references to it are gone by implementing the java.rmi.server.Unreferenced interface. This interface contains a single method, "public void unreferenced ()". This method is called when RMI determines that no client references exist for the object.
As mentioned above, there is no real way for RMI to tell that a client reference is gone. The Unreferenced interface uses a variety of techniques, any of which will result in a call to the unreferenced method. The techniques are:
No client calls for some amount of time
The default timeout is ten minutes, but that can be changed (see page 360 in your text for an example of this...the number you pass is the number of milliseconds for the timeout). If no client has accessed the server object in that amount of time, RMI assumes that all client references are gone and calls the unreferenced method.
Note that this method is not a guarantee that no references still exist, only that they have not been used for some amount of time.
All stubs are garbage collected
Another way RMI keeps track of client references to server objects is by keeping track of the stubs in the clients. For each remote object the client accesses, the client creates an instance of a stub. When that stub is garbage collected, it sends a message to the server to let it know the reference is gone. This allows RMI on the server to call the unreferenced method when all client stubs have been garbage collected, meaning no references still exist to the server object.
Again, this is not foolproof. Different Java virtual machines have different policies on when unreferenced objects (the stubs) are garbage collected. Some JVMs may never garbage collect the stubs.
In general, it is best to have clients send messages to the server when they exit, so the server can cleanup any data structures that may contain client information (for example, in a chat server, the server may maintain a list of users and callback instances). The server can then use the garbage collection method to catch any clients that may have crashed without sending a message. You should not rely on remote garbage collection entirely, due to its limitations.
So far in your work with RMI, you've needed to make sure that all the .class files needed by the client are already on the client. In a real-world situation, this would mean the user downloading a possibly large .jar file containing all the .class files. If the .class files changed (because of a change in the server), then the user would need to download new versions of the files.
It is possible to have the client program download the other .class files from the server, so that the user only needs to download a relatively small program to start with...the other files are downloaded when that program is run. This ensures that the client is always using the most up-to-date version of the .class files.
To understand how to do this, we need to understand a bit about how Java classes are loaded in a normal Java application. When you run a Java application, you are actually running a single Java class. That single Java class is loaded and the main method is executed. Other classes are loaded only when needed by something called a "classloader". The classloader normally loads files from the classpath on your local machine, looking in each directory in the classpath until the correct .class file is found.
In a client/server application, the client will try to load classes normally. Classes that cannot be found on the client side will be loaded from the server side. The approach described in your text is for the server to tell RMI where these classes can be found. This approach has some limitations, though.
Compiling the client
When compiling the client, any class directly referenced in the client must be accessible at compile time. Normally this is not a problem, as you will compile the client and distribute only the client.class file to the user. The rest of the classes needed will be downloaded from the server.
Multiple Downloads
The client will download the classes from the server each time the program is run. This could mean quite a delay in starting the application, depending on the size of the classes being downloaded. This behavior depends in part on the JVM you're using, and whether it caches class files or not.
Your book and the CD that comes with it contains an example of the server setting the codebase property to allow the client to download class files.
A slightly different approach can avoid these limitations, but it requires quite a bit more work on your part. The basic idea is that, instead of using the classloader provided by Java, you write your own classloader. This classloader can then connect to a server for downloading class files. Class files can be cached on the local machine, and marked with version numbers so that they are only downloaded again when they have changed. You could even program it all to keep track of dependencies between different files. Since you would be programming the classloader, it could be as sophisticated as you would like.
This article gives an example of writing a classloader that loads classes from a web server.
As we saw last week, to run an RMI application you need to start the server so it is waiting for client connections. If you are running many servers, you may have many programs running and waiting for network connections. Depending on the type of client/server application you are writing, you may want instead to have the server run only when a client tries to connect.
A program called "rmid" must be running on the server to allow for dynamic server activation. In addition, the server object must now be changed, as follows:
Another program must be written, to register the server object with rmid. This program must be run only once, after rmid is started. An example of this program in in your text, on page 365.
The main difference between a server that extends UnicastRemoteObject and a server that extends Activatable is in the server skeleton. The skeleton for a UnicastRemoteObject simply handles marshalling and unmarshalling of data. The skeleton for an Activatable object also handles starting a new instance of the server object if necessary.
There is much more available with this topic than we've covered here. For more details, see the Java Activation Tutorial, available in the Java docs or at http://java.sun.com/j2se/1.4.2/docs/guide/rmi/activation.html .
For your assignments, the only piece of today's lecture you might want to use is the part on asynchronous communication. The rest of the advanced topics are not necessary for the assignment, so you should only use them once you have everything else working and if you want to play with the tecniques.
Next week we will start looking at JDBC, a way of using Java to communicate with databases. Your RMI programming assignment is also due next week.